编程之外的智慧-Excel在数据处理中的妙用
起因
接到一个修改了一个bug的任务,进行了分析,发现关系表中有重复的数据, 发现原来的表中 没有针对 2个 字段 进行唯一索引,导致出现了这个问题.于是 本着 为了 以后 避免 重复 数据 的问题, 针对 2个 字段 进行 唯一索引.但是 数据表中有重复数据,只能进行数据的清洗,清洗原则是:
- 清洗掉重复数据中 role_id 为0的数据
- 如果role_id 不为0 则清洗掉 get_time 比较大的数据
解决方案一
本着 一贯的思维 就是构造语句,然后删除重复的语句, 于是有了下面的语句:
- 查询 客户关系表 中 55 客户库的 warehouse_id,customer_id,extra_id,role_id, 然后按照 role_id 升序, get_time 降序 排序
1 | select warehouse_id, customer_id, extra_id,role_id,get_time from `customer_extra` where warehouse_id = 55 order by role_id asc, get_time desc |
- 最后组合成删除的语句:
1 | DELETE FROM `5k_customer_extra` WHERE extra_id in (select t.extra_id from (select a.extra_id as extra_id from (select warehouse_id,customer_id,extra_id,role_id,get_time from `5k_customer_extra` where warehouse_id = 55 order by role_id asc,get_time desc) a group by CONCAT(a.warehouse_id, '_', a.customer_id) having count(*) > 1) t) |
搞定,感觉 不错的样子,于是在测试服务器上运行一下子,完美执行. 于是对接线上服务器高高兴兴的执行了一下, 然后 线上 系统 瞬间 访问 卡死, 然后群里立马各种问候就来了,这就很尴尬滴一说.
解决方案二:
上面执行了SQL 发现系统卡成屎,所以得查一下原因, SQL语句没有问题 于是 查了一下数据库中的数据:
1 | SELECT count(1) FROM customer_extra WHERE warehouse_id = 55; |
查询的结果果然喜人: 120万
于是 上代码 慢慢按照 1000 条删除一次的原则进行:
1 | # 创建一个游标 |
运行后, 线上系统是不卡嘞, 但是 这个代码 处理的速度 有点 太喜人嘞, 一分钟 才删除几万条不到, 尴尬,这个方案也是不行
解决方案三
于是, 本着 试试看的心态, 把数据导出来成 excel 格式
1 |
|
导出EXCEL如下:
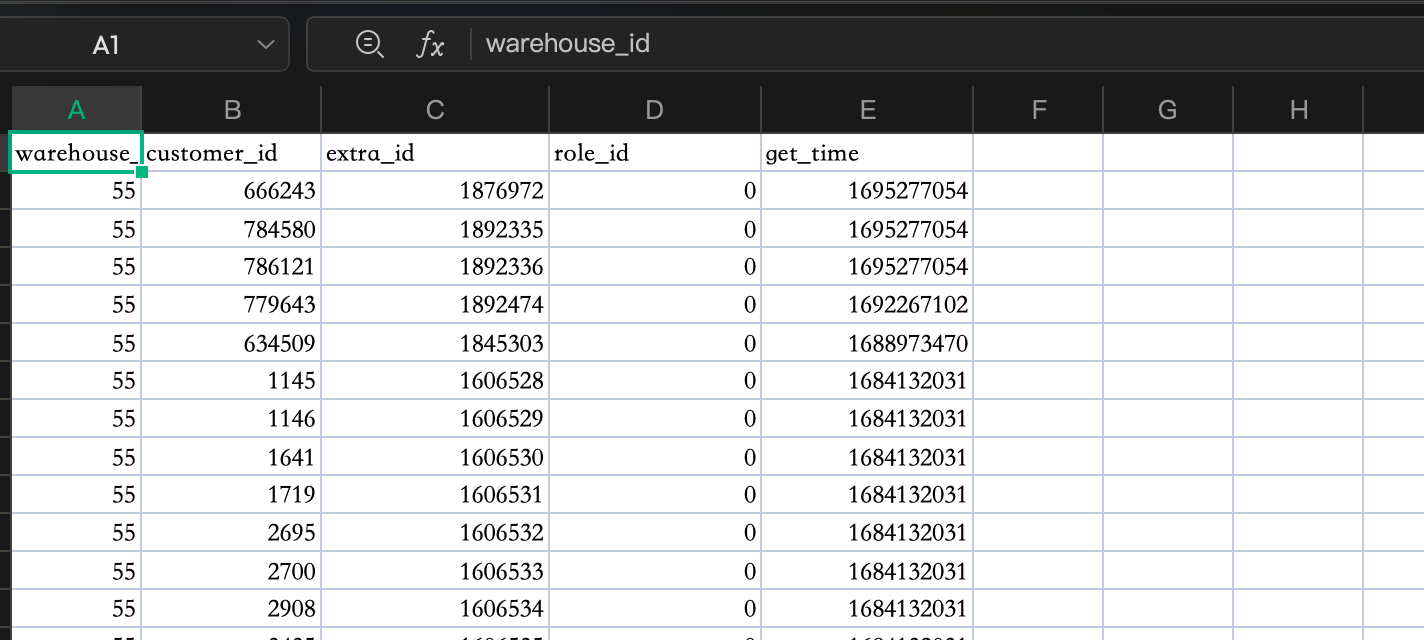
开始操作:
- 如图所示,查询公式 做出唯一键:

- 然后按照唯一键分组,如下图:
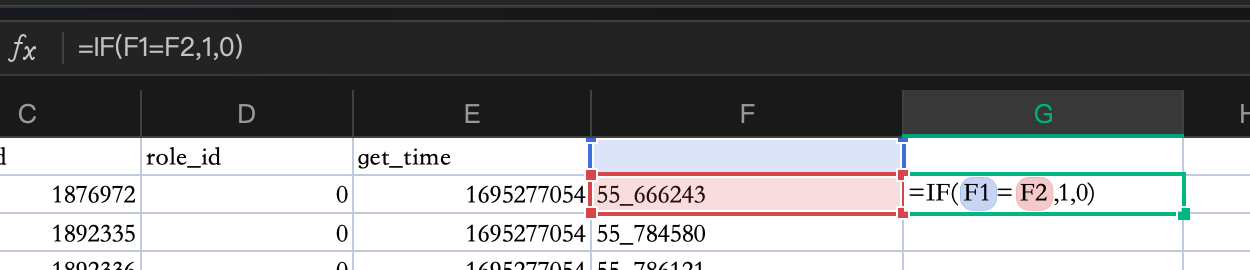
筛选,唯一键 拿到 为 1 的 就是重复的数据, 并且对 role_id 筛选 拿到 role_id 为 0的 先删除掉 一批
然后删按照 get_time 排序 删除掉 role_id 不为0 的数据.
OK 这样的操作比前面单纯跑 SQL 快多了,所以 方案三 可行. 但是 操作 Excel 不知道 其他熟练不, 反正我用起来 磕磕巴巴滴, 还得花点时间. 于是 就有嘞下面的操作
解决方案四
- 先运行 上面的查询SQL 然后 导出要删除的 主键ID
1 | SELECT t.extra_id |
导出来以后, 直接 整理 id 然后 放到代码里删除
1 | DELETE FROM `customer_extra` WHERE extra_id IN (....) |
速度比 操作 excel快多了, 然后一早上清理 完成, 然后果断执行 新建了一个唯一索引:
1 |
|